機器學習開發者想要打造一款 App 有多難?事實上,你只需要會 Python 程式碼就可以了,剩下的工作都可以交給一個工具。近日,Streamlit 聯合創始人 Adrien Treuille 撰文介紹其開發的機器學習工具開發框架——Streamlit,這是一款專為機器學習工程師建立的免費、開源 app 構建框架。這款工具可以在你寫 Python 程式碼的時候,實時更新你的應用。目前,Streamlit 的 GitHub Star 量已經超過 3400,在 medim 上的熱度更是達到了 9000+。
Streamlit 網站:https://streamlit.io/
GitHub地址:https://github.com/streamlit/streamlit/
用 300 行 Python 程式碼,程式設計一個可實時執行神經網路推斷的語義搜尋引擎。
以我的經驗,每一個不平凡的機器學習專案都是用錯誤百出、難以維護的內部工具整合而成的。這些工具通常用 Jupyter Notebooks 和 Flask app 寫成,很難部署,需要對客戶端伺服器架構(C/S 架構)進行推理,且無法與 Tensorflow GPU 會話等機器學習元件進行很好的整合。
我第一次看到此類工具是在卡內基梅隆大學,之後又在伯克利、Google X、Zoox 看到。這些工具最初只是小的 Jupyter notebook:感測器校準工具、模擬對比 app、鐳射雷達對齊 app、場景重現工具等。
當一個工具越來越重要時,專案經理會介入其中:程序和需求不斷增加。這些單獨的專案變成程式碼指令碼,並逐漸發展成為冗長的「維護噩夢」……
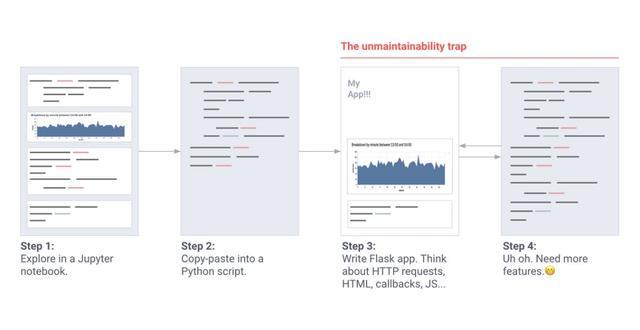
機器學習工程師建立 app 的流程(ad-hoc)。
而當一個工具非常關鍵時,我們會組建工具團隊。他們熟練地寫 Vue 和 React,在膝上型電腦上貼滿宣告式框架的貼紙。他們的設計流程是這樣式的:

工具團隊構建 app 的流程(乾淨整潔,從零開始)。
這簡直太棒了!但是所有這些工具都需要新功能,比如每週上線新功能。然而工具團隊可能同時支援 10 多個專案,他們會說:「我們會在兩個月內更新您的工具。」
我們返回之前自行構建工具的流程:部署 Flask app,寫 HTML、CSS 和 JavaScript,嘗試對從 notebook 到樣式表的所有一些進行版本控制。我和在 Google X 工作的朋友 Thiago Teixeira 開始思考:如果構建工具像寫 Python 指令碼一樣簡單呢?
我們希望在沒有工具團隊的情況下,機器學習工程師也能構建不錯的 app。這些內部工具應該像機器學習工作流程的副產品那樣自然而然地出現。寫此類工具感覺就像訓練神經網路或者在 Jupyter 中執行點對點分析(ad-hoc analysis)!同時,我們還想保留強大 app 框架的靈活性。我們想創造出令工程師驕傲的好工具。
我們希望的 app 構建流程如下:
Streamlit app 構建流程。
與來自 Uber、Twitter、Stitch Fix、Dropbox 等的工程師一道,我們用一年時間創造了 Streamlit,這是一個針對機器學習工程師的免費開源 app 框架。不管對於任何原型,Streamlit 的核心原則都是更簡單、更純粹。
Streamlit 的核心原則如下:
1. 擁抱 Python
Streamlit app 是完全自上而下執行的指令碼,沒有隱藏狀態。你可以利用函式呼叫來處理程式碼。只要你會寫 Python 指令碼,你就可以寫 Streamlit app。例如,你可以按照以下程式碼對螢幕執行寫入操作:
import streamlit as stst.write('Hello, world!')2. 把 widget 視作變數
Streamlit 中沒有 callback!每一次互動都只是自上而下重新執行指令碼。該方法使得程式碼非常乾淨:
import streamlit as stx = st.slider('x')st.write(x, 'squared is', x * x)3 行程式碼寫成的 Streamlit 互動 app。
3. 重用資料和計算
如果要下載大量資料或執行復雜計算,怎麼辦?關鍵在於在多次執行中安全地重用資訊。Streamlit 引入了 cache primitive,它像一個持續的預設不可更改的資料儲存器,保障 Streamlit app 輕鬆安全地重用資訊。例如,以下程式碼只從 Udacity 自動駕駛專案(https://github.com/udacity/self-driving-car)中下載一次資料,就可得到一個簡單快速的 app:
使用 st.cache,在 Streamlit 多次執行中儲存資料。程式碼執行說明,參見:https://gist.github.com/treuille/c633dc8bc86efaa98eb8abe76478aa81#gistcomment-3041475。
執行以上 st.cache 示例的輸出。
簡而言之,Streamlit 的工作流程如下:
每次使用者互動均需要從頭執行全部指令碼。Streamlit 根據 widget 狀態為每個變數分配最新值。快取保證 Streamlit 重用資料和計算。如下圖所示:
使用者事件觸發 Streamlit 從頭開始重新執行指令碼。不同執行中僅保留快取。
感興趣的話,你可以立刻嘗試!只需執行以下行:
這些想法很簡潔,但有效,使用 Streamlit 不會妨礙你建立豐富有用的 app。我在 Zoox 和 Google X 工作時,看著自動駕駛汽車專案發展成為數 G 的視覺資料,這些資料需要搜尋和理解,包括在影象資料上執行模型進而對比效能。我看到的每一個自動駕駛汽車專案都有整支團隊在做這方面的工具。
在 Streamlit 中構建此類工具非常簡單。以下 Streamlit demo 可以對整個 Udacity 自動駕駛汽車照片資料集執行語義搜尋,對人類標註的真值標籤進行視覺化,並在 app 內實時執行完整的神經網路(YOLO)。
這個 300 行程式碼寫成的 Streamlit demo 結合了語義視覺搜尋和互動式神經網路推斷。
整個 app 只有 300 行 Python 程式碼,其中大部分是機器學習程式碼。事實上,整個 app 裡只有 23 次 Streamlit 呼叫。你可以試試看:
我們與機器學習團隊合作,為他們的專案而努力時,逐漸意識到這些簡單的想法會帶來大量重要的收益:
Streamlit app 是純 Python 檔案。你可以使用自己喜歡的編輯器和 debugger。
我用 Streamlit 構建 app 時喜歡用 VSCode 編輯器(左)和 Chrome(右)。
純 Python 程式碼可與 Git 等原始碼控制軟體無縫對接,包括 commits、pull requests、issues 和 comment。由於 Streamlit 的底層語言是 Python,因此你可以免費利用這些協作工具的好處。
Streamlit app 是 Python 指令碼,因此你可以使用 Git 輕鬆執行版本控制。
快取簡化計算流程。一連串快取函式自動創建出高效的計算流程!你可以嘗試以下程式碼:
Streamlit 中的簡單計算流程。執行以上程式碼,參見說明:https://gist.github.com/treuille/ac7755eb37c63a78fac7dfef89f3517e#gistcomment-3041436。
基本上,該流程涉及載入元資料到建立摘要等步驟(load_metadata → create_summary)。該指令碼每次執行時,Streamlit 僅需重新計算該流程的子集即可。
為了保證 app 的可執行性,Streamlit 僅計算更新 UI 所必需的部分。
Streamlit 適用於 GPU。Streamlit 可以直接訪問機器級原語(如 TensorFlow、PyTorch),並對這些庫進行補充。例如,以下 demo 中,Streamlit 的快取儲存了整個英偉達 PGGAN。該方法可使使用者在更新左側滑塊時,app 執行近乎即時的推斷。
該 Streamlit app 使用 TL-GAN 展示了英偉達 PGGAN 的效果。
Streamlit 是免費開源庫,而非私有 web app。你可以本地部署 Streamlit app,不用提前聯絡我們。你甚至可以在不聯網的情況下在膝上型電腦上本地執行 Streamlit。此外,現有專案也可以漸進地使用 Streamlit。
漸進地使用 Streamlit 的幾種方式。
以上只是 Streamlit 功能的冰山一角而已。它最令人興奮的一點是,這些原語可以輕鬆組成複雜 app,但看起來卻只是簡單指令碼。這就要涉及架構運作原理和功能了,本文暫不談及。
Streamlit 元件圖示。
原文連結:https://towardsdatascience.com/coding-ml-tools-like-you-code-ml-models-ddba3357eace
參考文獻:
[1] J. Redmon and A. Farhadi, YOLOv3: An Incremental Improvement (2018), arXiv.
[2] T. Karras, T. Aila, S. Laine, and J. Lehtinen, Progressive Growing of GANs for Improved Quality, Stability, and Variation (2018), ICLR.
[3] S. Guan, Controlled image synthesis and editing using a novel TL-GAN model (2018), Insight Data Science Blog.